6. Feature Engineering¶
Feature Engineering is one of the most important part of model building. Collecting and creating of relevant features from existing ones are most often the determinant of a high prediction value.
- They can be classified broadly as:
- Aggregations
- Rolling/sliding Window (overlapping)
- Tumbling Window (non-overlapping)
- Transformations
- Decompositions
- Interactions
6.1. Manual¶
6.1.1. Decomposition¶
6.1.1.1. Datetime Breakdown¶
Very often, various dates and times of the day have strong interactions with your predictors. Here’s a script to pull those values out.
def extract_time(df):
df['timestamp'] = pd.to_datetime(df['timestamp'])
df['hour'] = df['timestamp'].dt.hour
df['mth'] = df['timestamp'].dt.month
df['day'] = df['timestamp'].dt.day
df['dayofweek'] = df['timestamp'].dt.dayofweek
return df
To get holidays, use the package holidays
import holidays
train['holiday'] = train['timestamp'].apply(lambda x: 0 if holidays.US().get(x) is None else 1)
6.1.1.2. Time-Series¶
Decomposing a time-series into trend (long-term), seaonality (short-term), residuals (noise). There are two methods to decompose:
- Additive—The component is present and is added to the other components to create the overall forecast value.
- Multiplicative—The component is present and is multiplied by the other components to create the overall forecast value
Usually an additive time-series will be used if there are no seasonal variations over time.
import statsmodels.api as sm
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
res = sm.tsa.seasonal_decompose(final2['avg_mth_elect'], model='multiplicative')
res.plot();
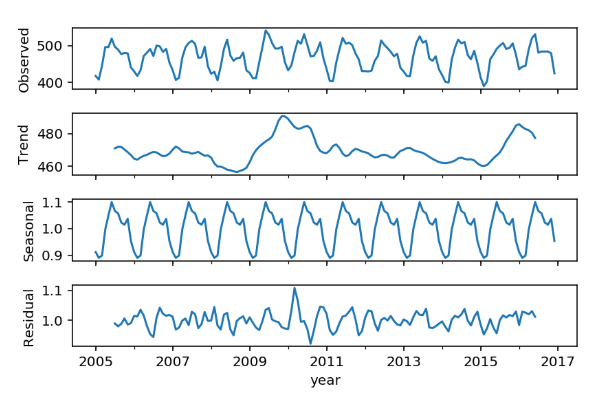
# set decomposed parts into dataframe
decomp=pd.concat([res.observed, res.trend, res.seasonal, res.resid], axis=1)
decomp.columns = ['avg_mth','trend','seasonal','residual']
decomp.head()
6.1.1.3. Fourier Transformation¶
The Fourier transform (FT) decomposes a function of time (a signal) into its constituent frequencies, i.e., converts amplitudes into frequencies.
6.1.1.4. Wavelet Transform¶
Wavelet transforms are time-frequency transforms employing wavelets. They are similar to Fourier transforms, the difference being that Fourier transforms are localized only in frequency instead of in time and frequency. There are various considerations for wavelet transform, including:
- Which wavelet transform will you use, CWT or DWT?
- Which wavelet family will you use?
- Up to which level of decomposition will you go?
- Number of coefficients (vanishing moments)
- What is the right range of scales to use?
- http://ataspinar.com/2018/12/21/a-guide-for-using-the-wavelet-transform-in-machine-learning/
- https://www.kaggle.com/jackvial/dwt-signal-denoising
- https://www.kaggle.com/tarunpaparaju/lanl-earthquake-prediction-signal-denoising
import pywt
# there are 14 wavelets families
print(pywt.families(short=False))
#['Haar', 'Daubechies', 'Symlets', 'Coiflets', 'Biorthogonal', 'Reverse biorthogonal',
#'Discrete Meyer (FIR Approximation)', 'Gaussian', 'Mexican hat wavelet', 'Morlet wavelet',
#'Complex Gaussian wavelets', 'Shannon wavelets', 'Frequency B-Spline wavelets', 'Complex Morlet wavelets']
# short form used in pywt
print(pywt.families())
#['haar', 'db', 'sym', 'coif', 'bior', 'rbio',
#'dmey', 'gaus', 'mexh', 'morl',
#'cgau', 'shan', 'fbsp', 'cmor']
# input wavelet family, coefficient no., level of decompositions
arrays = pywt.wavedec(array, 'sym5', level=5)
df3 = pd.DataFrame(arrays).T
# gives two arrays, decomposed & residuals
decompose, residual = pywt.dwt(signal,'sym5')
6.2. Auto¶
Automatic generation of new features from existing ones are starting to gain popularity, as it can save a lot of time.
6.2.1. Tsfresh¶
tsfresh is a feature extraction package for time-series. It can extract more than 1200 different features, and filter out features that are deemed relevant. In essence, it is a univariate feature extractor.
https://tsfresh.readthedocs.io/en/latest/
Extract all possible features
from tsfresh import extract_features
def list_union_df(fault_list):
'''
Description
------------
Convert list of faults with a single signal value into a dataframe with an id for each fault sample
Data transformation prior to feature extraction
'''
# convert nested list into dataframe
dflist = []
# give an id field for each fault sample
for a, i in enumerate(verified_faults):
df = pd.DataFrame(i)
df['id'] = a
dflist.append(df)
df = pd.concat(dflist)
return df
df = list_union_df(fault_list)
# tsfresh
extracted_features = extract_features(df, column_id='id')
# delete columns which only have one value for all rows
for i in extracted_features.columns:
col = extracted_features[i]
if len(col.unique()) == 1:
del extracted_features[i]
Generate only relevant features
from tsfresh import extract_relevant_features
# y = is the target vector
# length of y = no. of samples in timeseries, not length of the entire timeseries
# column_sort = for each sample in timeseries, time_steps column will restart
# fdr_level = false discovery rate, is default at 0.05,
# it is the expected percentage of irrelevant features
# tune down to reduce number of created features retained, tune up to increase
features_filtered_direct = extract_relevant_features(timeseries, y,
column_id='id',
column_sort='time_steps',
fdr_level=0.05)
6.2.2. FeatureTools¶
FeatureTools is extremely useful if you have datasets with a base data, with other tables that have relationships to it.
We first create an EntitySet, which is like a database. Then we create entities, i.e., individual tables with a unique id for each table, and showing their relationships between each other.
https://github.com/Featuretools/featuretools
import featuretools as ft
def make_entityset(data):
es = ft.EntitySet('Dataset')
es.entity_from_dataframe(dataframe=data,
entity_id='recordings',
index='index',
time_index='time')
es.normalize_entity(base_entity_id='recordings',
new_entity_id='engines',
index='engine_no')
es.normalize_entity(base_entity_id='recordings',
new_entity_id='cycles',
index='time_in_cycles')
return es
es = make_entityset(data)
es
We then use something called Deep Feature Synthesis (dfs) to generate features automatically.
Primitives are the type of new features to be extracted from the datasets. They can be
aggregations (data is combined) or transformation (data is changed via a function) type of extractors.
The list can be found via ft.primitives.list_primitives().
External primitives like tsfresh, or custom calculations can also be input into FeatureTools.
feature_matrix, feature_names = ft.dfs(entityset=es,
target_entity = 'normal',
agg_primitives=['last', 'max', 'min'],
trans_primitives=[],
max_depth = 2,
verbose = 1,
n_jobs = 3)
# see all old & new features created
feature_matrix.columns
FeatureTools appears to be a very powerful auto-feature extractor. Some resources to read further are as follows: